
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 딥러닝
- 북마크한 목록 가져오기
- 머신러닝
- 프론트엔드
- DRF
- serializer
- js
- 다항 논리 회귀
- ERD
- 이진 논리 회귀
- 댓글지우기
- 와이어프레임
- test.py
- 비밀번호 수정
- Python
- python to json
- 개인페이지
- original set
- CNN
- 댓글쓰기
- 프로필사진 업로드
- 팔로우 기능 에러
- 장고
- API명세
- 백엔드
- Django
- 팀프로젝트 기획
- class view
- docker
- json to db
- Today
- Total
코딩 개발일지
머신러닝 기초 - 딥러닝 / Overfitting 본문

우리가 지금까지 배운 선형회귀와 논리회귀만으로는 결코 실무에서 쓸 수는 없는게 당연함.
선형회귀를 아무리 반복해봤자 비선형이 되는게 아니기때문에,
선형회귀 사이에 비선형의 무언가를 넣어야한다고 생각하게 된거다 !!!
딥러닝에서는 비선형 함수를 활성화 함수라고 한다.

딥러닝의 주요 개념과 기법
- 배치 사이즈와 에폭
- 활성화 함수
- 과적합과 과소적합
- 데이터 증강
- 드랍아웃
- 앙상블
- 학습률 조정
Deep Neural Networks 구성 방법
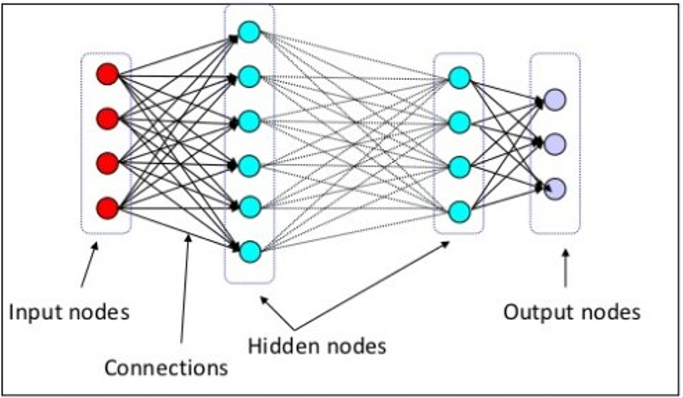
- Input layer(입력층): 네트워크의 입력 부분. 우리가 학습시키고 싶은 x 값
- Output layer(출력층): 네트워크의 출력 부분. 우리가 예측한 값, 즉 y 값
- Hidden layers(은닉층): 입력층과 출력층을 제외한 중간층입니다. 여개로 구성되어있다.
각 layer 하나하나가 Linear Regression (선형회귀) 여러개로 이루어져있다.
앞서 말했던 활성화 함수를 어디다가 넣어야하는지도 중요함. 보편적인 경우 모든 은닉층 바로 뒤에 위치한다.
네트워크의 너비를 늘리는 방법 : 네트워크의 은닉층의 개수를 그대로 두고 은닉층의 노드 개수를 늘리는 방법입니다.
네트워크의 깊이를 늘리는 방법 : 네트워크의 은닉층의 개수를 늘리는 방법입니다.
( 중요한 점은, input layer와 output layer의 갯수와 노드 수는 변할 수 없다. )
실무에서는 이런 방식으로 은닉층의 너비와 높이를 계속해서 많이 바꿔가면서 최적화된 모델을 만든다.
< batch / iteration / epoch > 을 쉽게 이해하는 그림

hidden layers 다음에 활성화함수가 존재한다고 앞서 말했다.
이 함수를 거쳐갈 때, 일정 임계치를 넘어야 다음 뉴런이 활성화 한다고해서 활성화 함수라고 부른다. (정의 / 개념)
활성화 함수는 비선형 함수여야 합니다. 위에서 딥러닝은 비선형 함수를 사용한다고 했었다고 다시 한번 강조 !!
비선형 함수의 대표적인 예가 바로 시그모이드 함수이다.
활성화함수에는 시그모이드 말고도 여러가지 종류가 있다.

위 사진을 보면 전부 다 비선형의 모양을 띄고있다.
딥러닝에서 가장 많이 보편적으로 쓰이는 활성화함수는 단연 ReLU(렐루)
다른 활성화 함수에 비해 학습이 빠르고, 연산 비용이 적고, 구현이 간단하기 때문이다.
Overfitting / Underfitting
한국어로 잘 안씀. 각 과적합, 과소적합이라고 한다.

이 사진이 가장 적절한 사진이다.
딥러닝 모델을 학습시키다보면 보통 Underfitting 보다는 Overfitting 때문에 골치를 썩는 경우가 많다.
이를 해결하는 대표적인 방법으로는 Data augmenation, Dropout 등이 있다.
- Data augmentation (데이터 증강기법)
실무에서 매번 거의 무조건 쓰는 기법이다.
<예시> 원본 이미지 한 장을 여러가지 방법으로 복사를 한다.

사람의 눈으로 보았을 때 위의 어떤 사진을 보아도 사자인 것처럼 딥러닝 모델도 똑같이 보도록 학습시킨다.
이 방법을 통해 더욱 강건한 딥러닝 모델을 만들 수 있음.
- Dropout (드랍아웃)
각 노드의 연결을 끊어버리는 작업이다. "사공이 많으면 배가 산으로 간다" 라는 속담을 떠올리면 된다.
과적합이 발생했을 때 적당한 노드들을 탈락시켜서 더 좋은 효과를 낼 수 있다.

Dropout은 과적합 발생시 생각보다 좋은 효과를 낸다. 그리고 사용하기도 아주 간단함.
실무에서 과적합이 발생한다면 꼭 한 번 사용해보자 !!!!!
- Ensemble (앙상블)
앙상블 기법은 컴퓨팅 파워만 충분하다면 가장 시도해보기 쉬운 방법이다.
여러개의 딥러닝 모델을 만들어 각각 학습시킨 후 각각의 모델에서 나온 출력을 기반으로 투표를 하는 방법.
(다수결(?) 느낌)
앙상블을 사용할 경우 최소 2% 이상의 성능 향상 효과를 볼 수 있다고 알려져 있다.
- Learning rate decay (Learning rate schedules)
그대로 해석해서 이해하면된다. Learning rate 를 붕괴(?)부패(?) 시킨다.
< 왼쪽 사진이 decay / 오른쪽 사진이 일정한 Learning rate >

Keras에서는
tf.keras.callbacks.LearningRateScheduler()
tf.keras.callbacks.ReduceLROnPlateau()를 사용하여 학습중 Learning rate를 조절한다.
- Colab에서 지금까지는 CPU를 사용했는데 GPU를 사용하면 딥러닝의 연산속도를 대폭 향상시킬 수 있다 !
[런타임] - [런타임 유형 변경] - 하드웨어 가속기 GPU 선택 저장
'AI 본 교육 > AI 10주차' 카테고리의 다른 글
| 머신러닝 기초 - CNN 실습 / 전이학습 실습 (3) | 2023.10.19 |
|---|---|
| 머신러닝 기초 - CNN의 개념 / Pooling / Model (1) | 2023.10.19 |
| 머신러닝 기초 - 이진/다항 논리 회귀 (Logistic regression) (1) | 2023.10.18 |
| 머신러닝 기초 - 선형회귀, original set, 간단한 용어 설명 (0) | 2023.10.17 |



